What is deduplication?
The deduplication is a technique of lossless data compress that eliminates redundant data as intra-file as inter-file, different tools to data compression like gzip only eliminates the redundancy intra-file. The deduplication reduces storage needs through eliminating redundant blocks or files. In the deduplication, all data blocks or files that are duplicates in a storage system are reduced to a solely copy, and the unallocated data are transformed in reference to the data content maintained in the system.
How does Dedupeer work?
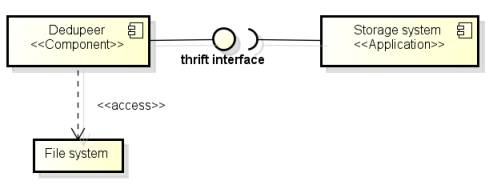
Dedupeer was development as a software component with Apache Thrift interface to facility cross-language communication between the storage system and the algorithm, which was development in Java. The Dedupeer runs a Thrift server and have the method signature listening for clients request:
where hashesToCompare is a object of type
The object ChunkIDs has been defined in the Thrift this way:
The complete Thrift document of the Dedupeer Project is hosted here
The Apache Thrift supports communication between this languages: As3, C Glib, C++, CSharp, D, Delphi, Erlang, Go, Haskell, Java, Java Me, Javascript, Node.js, Objective-c, OCaml, Perl, PHP, Python, Ruby, Smalltalk. For more information, visite this link: http://thrift.apache.org/tutorial/
Below, a representation of the component diagram for this communication.
The Algorithm
Two algorithms were developed in the Academic Master, the first is a simple algorithm that loads the whole file in the memory to be processed, and the second splits the file in segments to be loaded into memory at a time. Both were based in the rysnc algorithm.
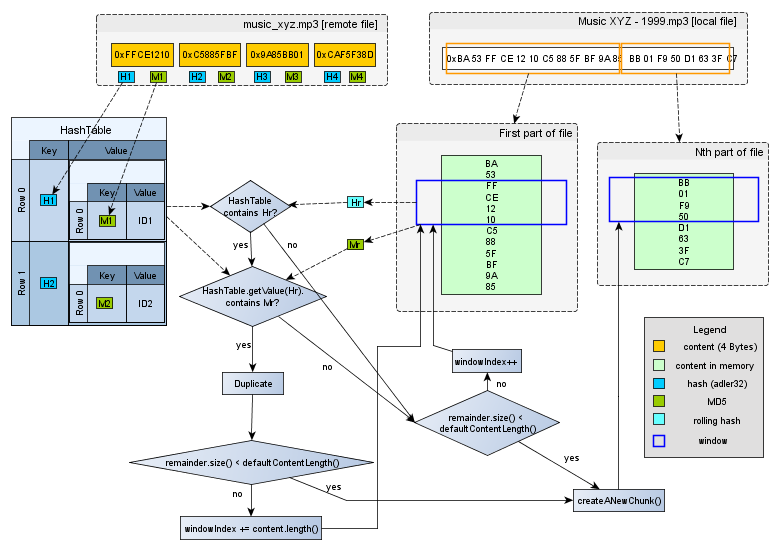
Below, was summarized the second and the most complex of two algorithms. The complete algorithm coded in Java can be found in here. The main difference between the first and the second algorithms is the processing form, in the second the file can be processed in parts, which are loaded to the memory in parts with size defined by user of the Thrift service.